This is a composite case study, drawn from several stalled EAM implementations we’ve been called in to recover over the past several years. The details are anonymized and aggregated, none of them describe any specific client, but the pattern is real, and it repeats often enough that it’s worth writing down.
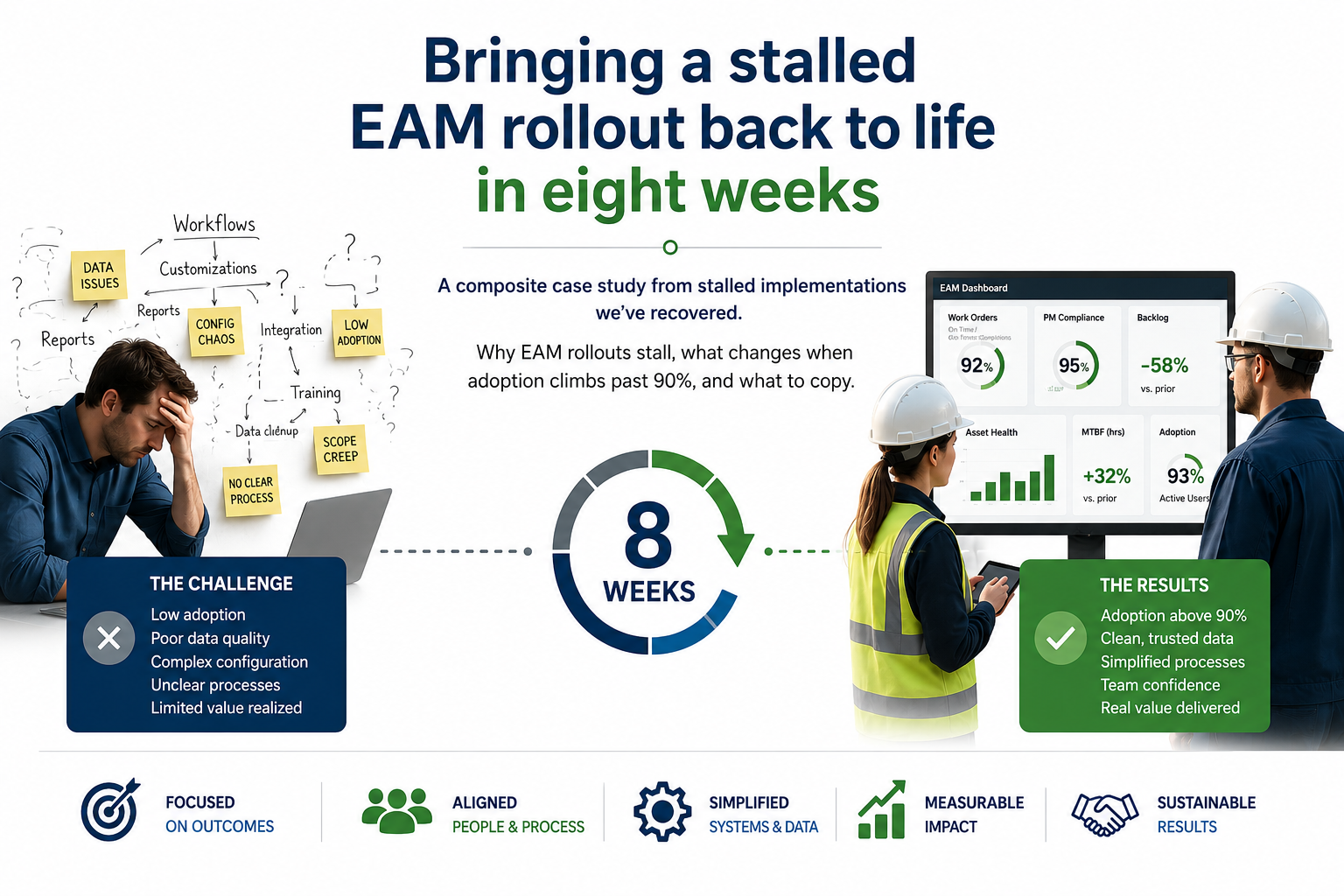
What follows is the rough shape of how that turnaround happens, and what consistently has to be in place for it to work.
Where it started: eighteen months in, stalled
By the time we’re typically called in, the symptoms are familiar. Leadership asks why adoption is still in the teens after a year-plus of work. IT points to the system: “it’s configured per the original requirements; the planners just aren’t using it.” The planners, when asked privately, describe a system that takes too many clicks, surfaces the wrong fields, and doesn’t reflect how the work actually flows on the floor.
Each group is partly right. The system isn’t broken. The configuration matches the requirements that were captured. The planners aren’t lazy. But the requirements were captured in conference rooms, not in the field, and the design that came out of them never survived contact with Tuesday morning.
Weeks 1–2: Listening, watching, finding the friction
The first phase isn’t about the system. It’s about the work. Concretely, that means about ten days of:
- Sitting with two or three planners during their actual workflow. Not interviewing them. Watching them. Noting where they alt-tab to a spreadsheet, where they pick up the phone, where they stare at the screen waiting for it to load.
- Walking the floor with supervisors and field technicians. Understanding what they need from the system at the point of work, which is usually 80% less than what the system tries to give them.
- Pulling reports nobody uses and asking why. The unused reports are the cleanest signal of where the design missed the user.
At the end of two weeks, there’s a short document, usually fewer than twenty pages, describing what we observed. Not recommendations yet. Observations. The first time the planners see it, the typical reaction is “yes, exactly. Nobody’s ever written this down before.”
The diagnostic is the deliverable. Once everyone agrees on what’s actually happening, the recommendations almost write themselves.
Weeks 3–5: Workflow redesign, not configuration change
This is the phase where the work happens, and where most recovery efforts go wrong. The temptation is to immediately start changing configuration in the system, new screens, new fields, new rules. That’s the wrong order.
The right order is to redesign the workflow on paper first. Specifically:
- Re-map the work-order lifecycle from how it actually moves in your organization (not how the textbook says it should). Where does a request come from? Who triages it? When does it become a planned job? When does it get scheduled?
- Identify the three or four screens planners and supervisors actually use, and design those carefully. The rest of the system can wait.
- Decide what data has to be entered, by whom, and when. Most stalled rollouts ask too much data entry from people who can’t do it at the point of work. Cut the data requirements ruthlessly to what’s needed for the next decision, not what would be nice to have.
This work is mostly conversations with planners and supervisors. The output is a workflow document, validated by the people who’ll live in it, that everyone agrees would be faster than the current state. Then the configuration changes follow from the document, not the other way around.
Weeks 6–8: Re-launch with the planners who’ll own it
The re-launch isn’t a town hall. It’s a working pilot with the two or three planners and supervisors who participated in the redesign. They run live work through the new workflow for two to three weeks while the rest of the team watches.
This phase has three jobs:
Prove the new workflow is genuinely faster
The pilot planners need to be able to honestly say “this is now the fastest way to do my job.” If they can’t say that, the workflow isn’t ready and we need another adjustment cycle. Hitting that threshold is non-negotiable.
Make the pilot planners the trainers
Once the pilot is working, the planners who lived through it train their peers. Not a vendor trainer. Not a consultant. Their colleagues. Adoption climbs not because of a mandate but because the planner next to you is doing the same job in half the time.
Make the data quality fix visible
While workflow is being redesigned, the asset hierarchy and master data quietly get cleaned up in parallel. By re-launch, the data the planners see matches what’s actually in the field. The phrase “the system says X but the field says Y” stops appearing in meetings within two weeks. That’s the trust signal.
What the pattern looks like
The composite case ends with adoption past 90%, the parallel spreadsheets quietly retired, and the planners volunteering to be the trainers for the next site. But the more important outcome is that the program has internal owners. There are now three to five people in the client organization who understand exactly why the workflow is designed the way it is, can defend it when leadership turns over, and can train new hires on it without external help.
That’s the deliverable that actually compounds. Eight weeks of focused work is the visible win. The internal capability is the durable one.
Three ingredients that consistently appear
Across the implementations we’ve helped recover, three things show up in every successful recovery and are usually missing in the original rollout:
- Observation before recommendation. The original implementations almost always skipped sitting with the planners and watching the work. Once you do that, the design choices become obvious.
- Workflow design before configuration change. Configuration is downstream of workflow. Getting them in the wrong order is the most common single failure mode.
- Pilot adoption before broad rollout. Two or three planners who genuinely prefer the new workflow are more persuasive than any training program. Find them, work with them, let them lead.
None of this is glamorous. None of it requires a re-implementation. It requires the patience to listen first, the discipline to design before configuring, and the humility to let your planners be the heroes of their own system.